
论文阅读-Oblivious Database相关
不经意数据库相关研究
抵抗inference attack
关键是隐藏访问模式:隐藏访问内容+访问时间/访问次数/访问顺序等
ObliDB:star2:
Proceedings of the VLDB Endowment,Volume 13,Issue 2,October 2019
Stanford University
威胁模型:
- 读取并篡改不可信内存
- 暂停和恢复Enclave执行
- 观察到对不可信内存的访问模式
- 监听网络通信
- 了解存储的数据的辅助信息
- 无法突破SGX远程认证
- 假设:不经意内存有限
安全保证:
- 探测到任何篡改数据的恶意行为
- 只泄露查询选择率(select行的比例),表的大小(包括输出表和中间表)和查询方案
- 可选的padding模式,可以隐藏表的大小和查询选择率
- 在enclave外的数据经过加密和MAC计算,仅泄露大小
- 数据库中表的数量 & 查询了哪张表不作隐藏
Overview:
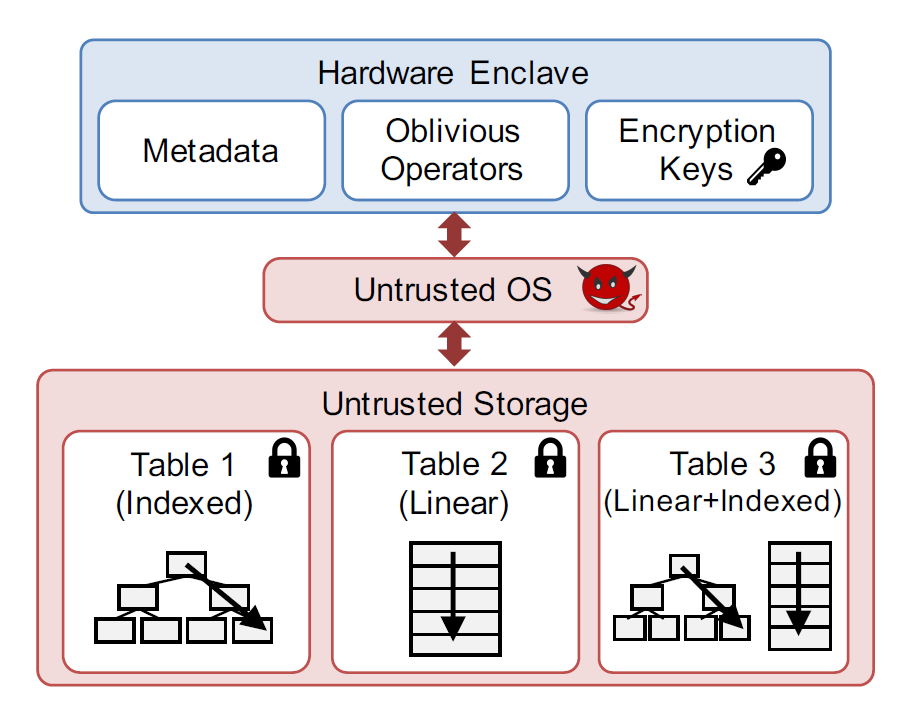
- 不经意数据库引擎支持小规模查询和分析查询(需要遍历整张表)
- 表加密存储在不可信内存但是访问模式被隐藏
- 两种存储方案:线性表、不经意索引(用于单点查询)
- Enclave用于存储密钥、元数据,不经意算子在Enclave中执行
存储方案
扁平化存储
数据存储在相邻的块中,每次读/写都需要访问所有块(整张表),用于存储:
- 小的表
- 操作后返回表的大部分区域的表
- 涉及读取全部或大部分表的分析
数据的插入、更新、删除需遍历整张表,对未受影响的块进行虚拟写(重新写一遍所有数据并重新加密)
索引存储
对B+树的插入/删除操作会泄露树的结构信息 => 使用虚拟ORAM访问,填充所有插入/删除操作,使其访问次数与最坏情况匹配
优化:
- 懒写回:只在必要的时候写入ORAM,否则将节点保留在enclave中
- 移除指向父节点的指针
Opaque
14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17)
UC Berkeley
Opaque relies on oblivious sorts over the entire dataset. These systems are not efficient for more general workloads that may also include point queries.【ObliDB】(单点查询效率低)
仅达到了Level 1的不经意性,因为使用不经意内存池进行优化【O-Join】
不经意分布式数据分析平台:
- 引入一系列新的分布式关系运算符
- 新的查询规划技术,rule-based和cost-based
- 三种运行模式:加密模式、不经意模式、不经意填充模式
威胁模型
- 观察和修改网络通信
- 获取操作系统的root权限
- 观察enclave对不可信内存的访问模式
- 可以进行回滚攻击,将密封的数据恢复到之前的状态
- 不能破坏可信硬件
- 对Opaque源码的访问是不经意的
安全保证
加密模式
- 数据加密和身份认证
- self-verifying integrity
不经意模式
- 隐藏访问模式,但不隐藏访问的数据大小,以及Catalyst选择的查询方案
不经意填充模式
- 在不经意模式的基础上,进一步隐藏数据大小和查询方案
Overview
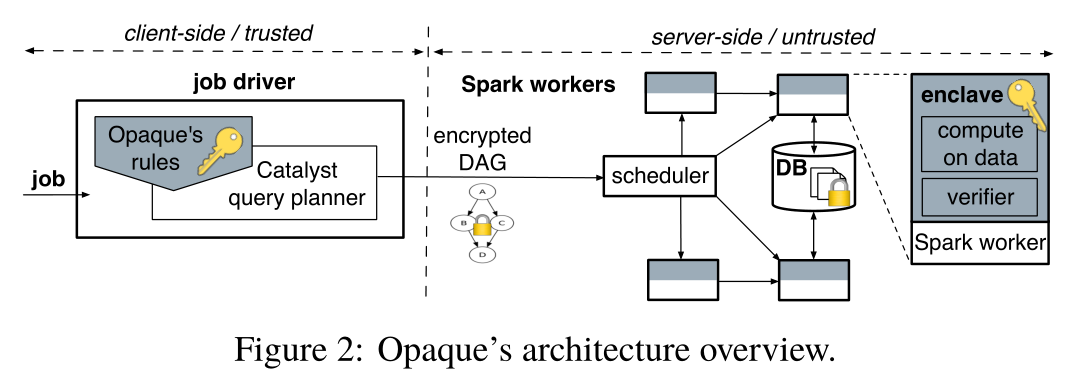
不经意执行
- 不经意排序(单机 & 分布式)
- 不经意过滤(filter)
- 不经意聚合(group)
- 不经意连接(join)
查询规划
- 成本模型:主要考虑不经意排序的次数
- 查询优化
- 混合敏感性:使用second path analysis来推断敏感表
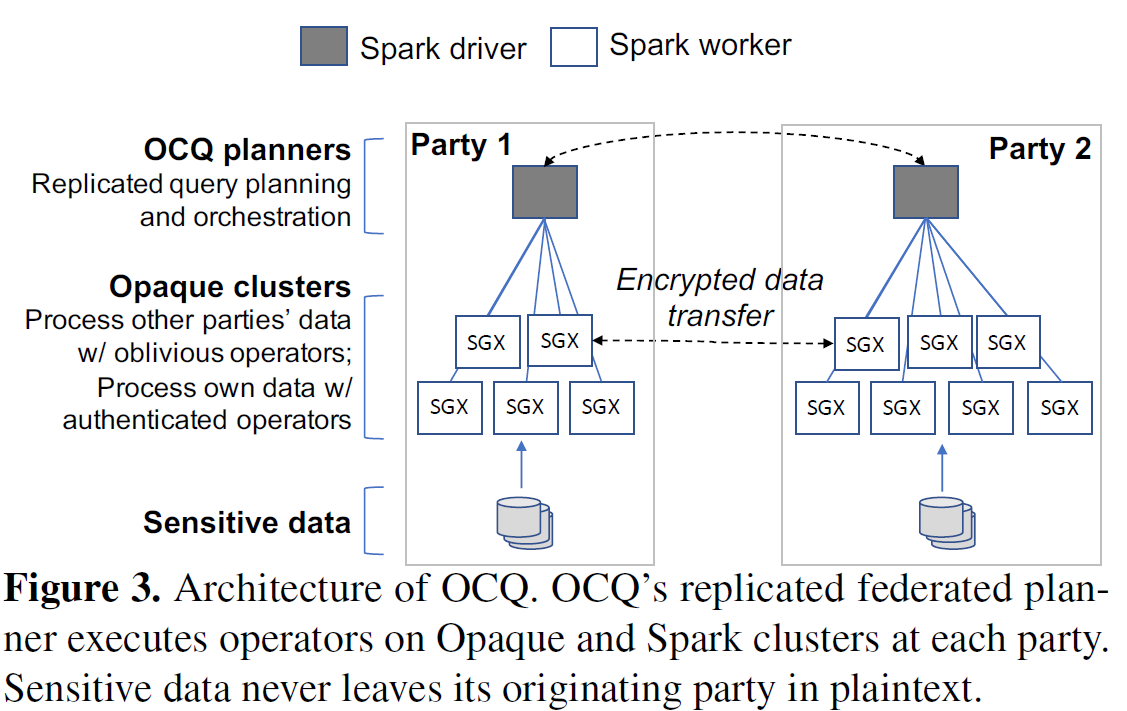
OCQ
Proceedings of the Fifteenth European Conference on Computer Systems 2020
UC Berkeley
OCQ[33]是一个不经意的协同竞争分析的通用框架,它建立在Opaque[87]的基础上,以分散的方式执行协同竞争查询。【Practical O-Join】
多方不经意竞争分析的解决方案,而不是设计一个数据库
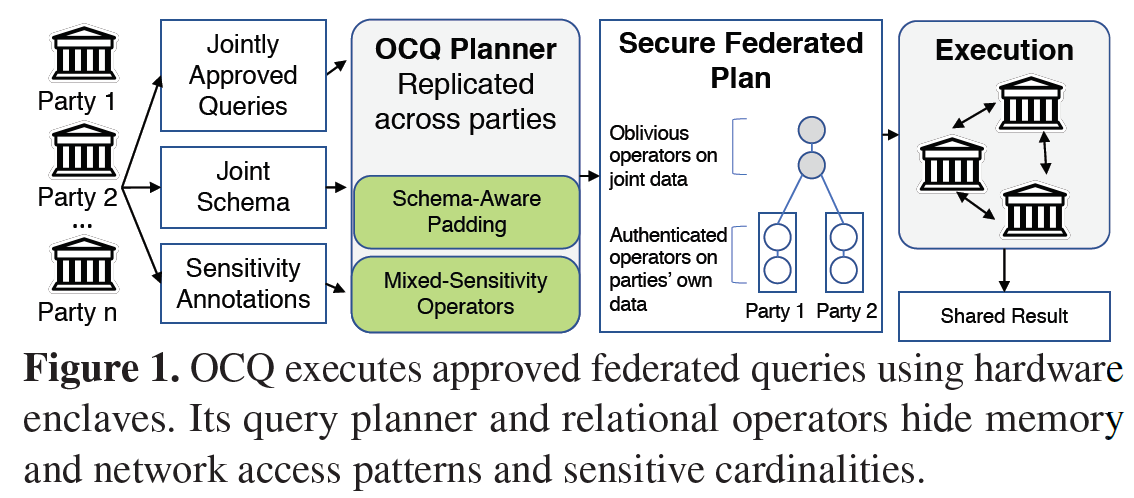
主要贡献:
- 不经意查询算法
- schema-aware填充机制:防止两种数据泄露——enclave中的数据泄露和enclave外网络通信中的模式泄露
- 不经意规划器:决定在哪执行操作以及如何执行
不经意算法:
Single-machine oblivious sorting can be done using sorting networks that perform a fixed sequence of compare-exchange operations. Asymptotically more compare-exchange operations are needed for oblivious sorting than for traditional sorting. An oblivious compare-exchange can be implemented via a comparison followed by a conditional swap of two equal-length buffers depending on the result of the comparison.
For data partitioned across multiple machines, oblivious sorting can be accomplished using a two-level sorting algorithm in which each partition is individually sorted using a sorting network, and records are sorted across partitions using an algorithm called column sort. Column sort consists of a fixed sequence of data exchange and intra-machine sorting
that uses only 4 shuffles, compared to O(nlog2n) shuffles for a sorting-network-based distributed sort.
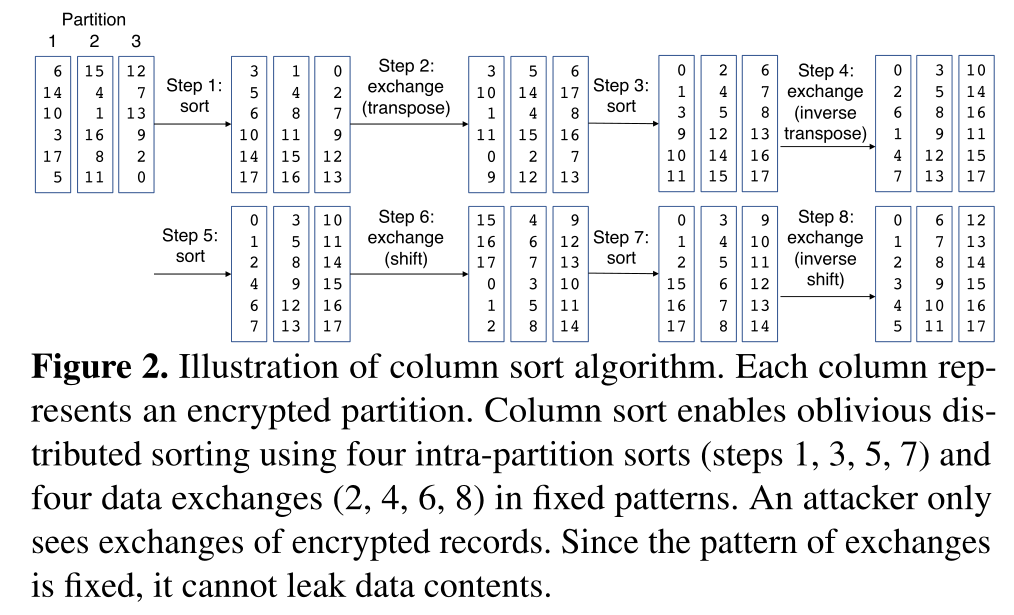
Overview
Oblivious join:star2:
Proceedings of the VLDB Endowment 2020
University of Waterloo 滑铁卢大学
-
提出时间复杂度为 $O(nlog^2n+mlogm)$ 的不经意equi-join算法,其中 $n$ 是输入表大小之和, $m$ 是输出表大小
- equi-join是指根据相等的条件来join两张表
-
该算法只依赖于能够在加密数据上支持sorting network的计算模型
-
不隐藏输出大小和运行时间
在加密数据上进行计算
- Outsourced External Memory
- Secure Cryptographic Coprocessors
- TEE
- Secure Multiparty Computation
- Fully Homomorphic Encryption
不经意性划分
- Level 1:对公共内存的访问是不经意的,但需要非常数量的本地内存来执行non-oblivious计算
- Level 2:对公共内存的访问是不经意的,且需要的本地内存大小是一个常数
- 访问程序的数据是不经意的,但是基于控制流访问的字节码没有隐藏。例如分支语句,条件本身是不经意的,但是跳转到的分支的字节码位置没有隐藏
- Level 3:程序的控制流,甚至处理器执行的指令,都与输入无关
将Level 2的程序转变为Level 3的程序需另外满足3条限制:
- 循环次数必须是常数(因为若根据变量来定循环次数,会很难隐藏执行循环的时间)
- 任何变量执行的最大分支数是一个常数
- 若一个程序暴露输出长度 $m$ ,则这一定在分配了 $m_0\in\Omega(m)$ 的内存之后
Overview
- 输入两张未排序的表 $T_1$ 和 $T_2$ ,分别包含 $n_1$ 和 $n_2$ 对 $(j,d)$ ,其中 $j$ 表示参与join条件判断的属性, $d$ 是其他属性。输出记为 $T_1\bowtie T_2={(d_1,d_2)|(j,d_1)\in T_1, (j,d_2)\in T_2}$
- 使用固定大小的本地内存来实现Level 2的不经意性
算法

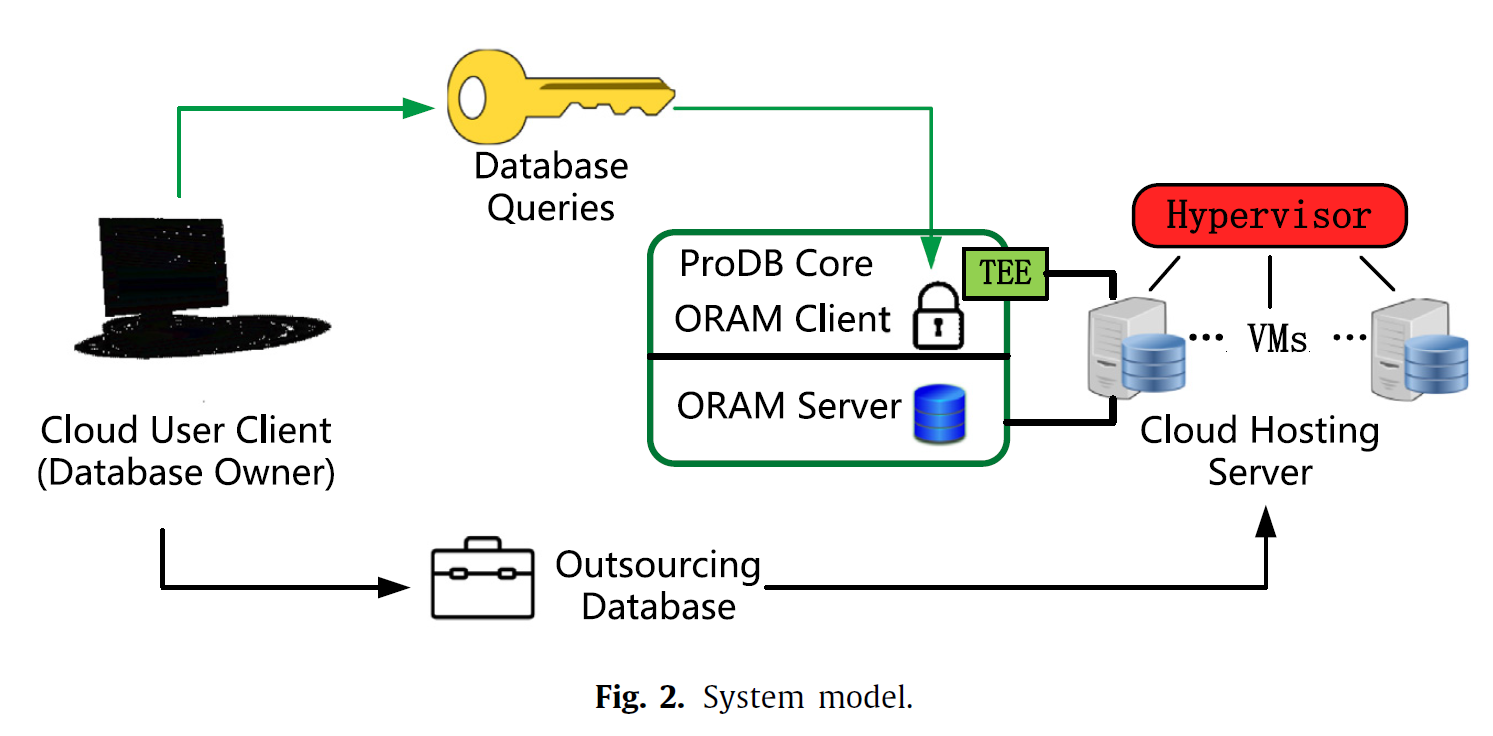
ProDB
Information Systems 2021
The Hong Kong Polytechnic University 香港理工大学
- 使用enclave+ORAM的方案来优化硬件资源不足的问题
- 提出SaP ORAM协议,用来实现enclave到不可信区的通信
- 不支持并发控制,回滚机制,数据库日志
Overview
-
安全模型:Memory-secure DBMS
-
two-tier设计:
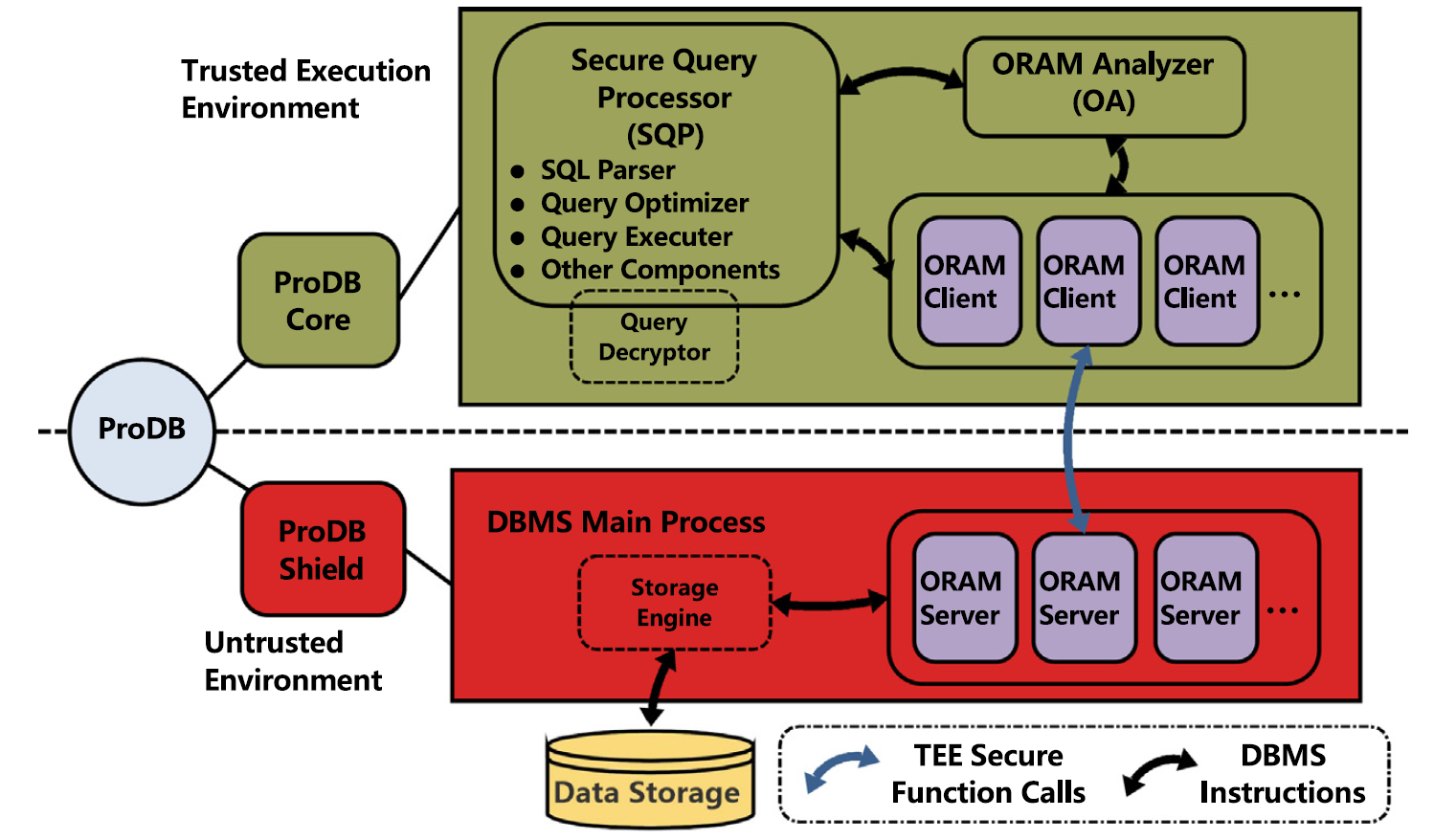
- core(部署在TEE中)
- SQL Decryptor:在TEE中解密SQL query
- Secure Query Processor (SQP):与传统处理query的组件相同,除了I/O access
- ORAM Analyzer (OA):利用SQL query历史信息的meta-data来规划最优的分配数据块到ORAM树path的方案
- ORAM Clients:每个client对应一个server,SQP通过client获取不可信内存中的数据
- shield(部署在不可信内存)
- DBMS Main Process:主程序
- ORAM Servers:树形结构,以ORAM-to-Disk机制将数据安全地写入磁盘
- core(部署在TEE中)
-
work-flow
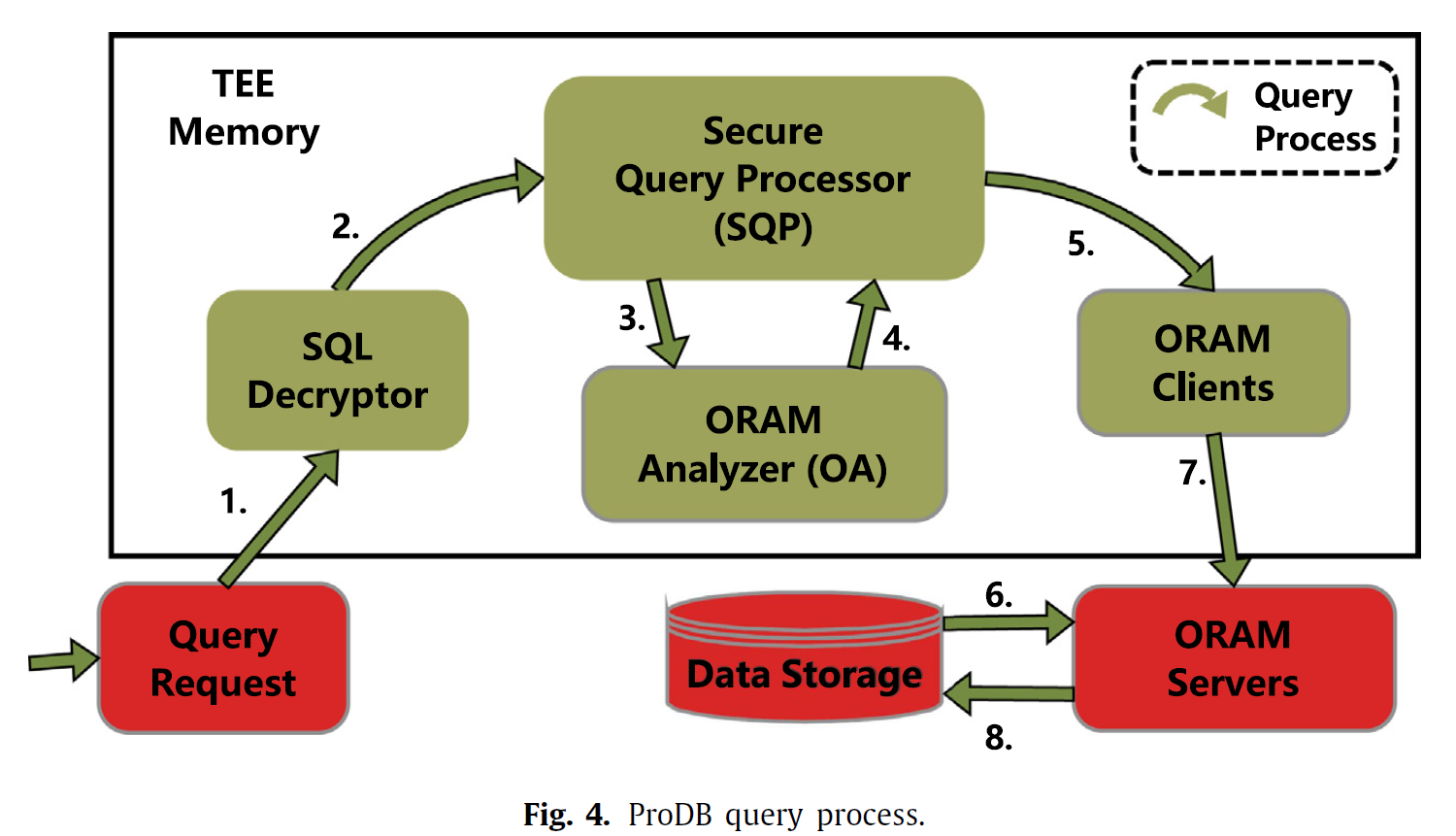

SaP ORAM
probabilistic lazy persistence
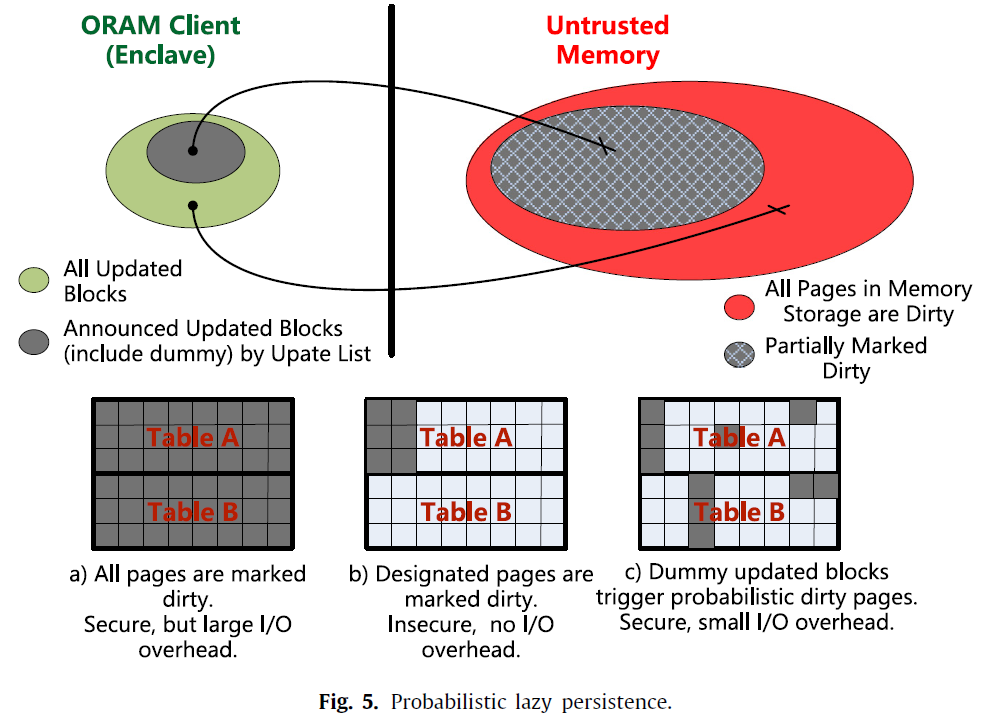
- Tagged position map:tag-address-path映射
- Update list:存储被SQL query更新的块(而不是被ORAM重加密更新的),不能被敌手知道哪些块在Update list中
- probabilistic dirty-block-generation procedure
SQL-aware path sharing
目的:减少查询内和查询间的ORAM轮数
核心思想:在一轮ORAM中从树的path中获取多个块(ORAM Analyzer跟踪那些经常一起访问的块,并尽可能多地将它们放在同一ORAM树路径中)
具体方案:没细看
Obladi
Proceedings of the 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI’18)
Cornell University
Obladi [28] considers concurrent ACID transactions but does not support indexes and only processes operations in batches over discrete time epochs.【ObliDB】
Obladi[32]是第一个在隐藏访问模式的同时提供ACID事务的系统。它批量处理操作,但不支持索引【Practical O-Join】
【主要是事务和并发的实现】
第一个提供ACID事务的kv数据库
- 容错机制
- 并发控制
Practical Oblivious Join
SIGMOD '22: Proceedings of the 2022 International Conference on Management of Data
西安电子科技大学,阿里巴巴
:star2:【参考文献整理】
-
对以往的不经意Join算法进行整理比较
-
提出了两种用于一般二元equi-join的不经意算法
- oblivious sort-merge join
- oblivious index nested-loop join
-
通过扩展index nested-loop join来支持一些band join(如"<“和”>")
-
使用index nested-loop join来支持多个表上的非循环equi-join
Oblivious Query Processing
- Microsoft Research
Contributions
- 对安全查询处理的形式化定义
- 设计占用较小TM(Trusted Module)的不经意算法
- 定理1(Informal):$O(log,n)$ TM空间占用的不经意算法的存在性
- 定理2(Informal):I/O复杂度
- 实现时间复杂度 $O(nlog,n)$ ,TM空间占用 $O(log,n)$ 的不经意算法
- ORAM-based算法时间复杂度的下界为 $\Omega(nlog^2n)$
- 除了不经意排序,所有算法都基于磁盘扫描;不经意排序基于磁盘搜索, 搜索次数 $O(log_{M/B}(n/B))\cdot o(n/B)$ 【M为TM内存,B为block大小】
- ORAM-based算法磁盘搜索次数 $\Omega(\frac{n}{BlogM}log^2{\frac{n}{B}})$
对比
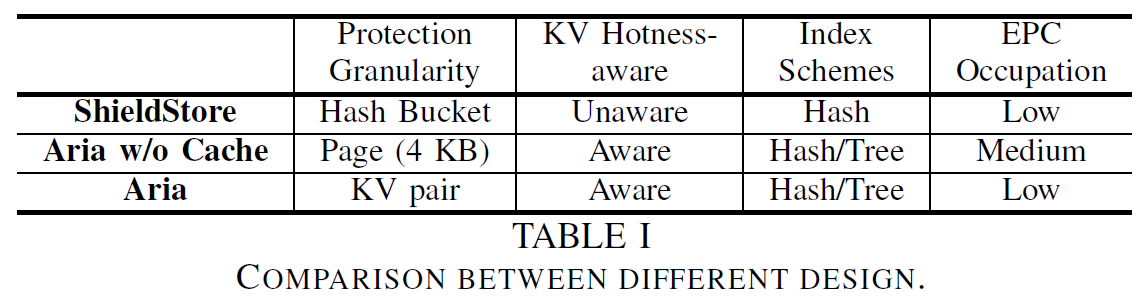
| 数据库类型 | 支持 | 特点 | 实现 | |
|---|---|---|---|---|
| ObliDB | 关系型 | 索引 | TEE+ORAM | |
| Opaque | Spark SQL | 分布式 | TEE | |
| OCQ | Opaque | 分布式 | TEE | |
| ProDB | DBMS(关系型) | SaP ORAM协议 | TEE+ORAM | |
| Obladi | kv数据库 | 事务 | 并发ORAM | ORAM |
| CODBS | 关系型(PostgresSQL) | 索引 | 形式化证明:star2: | TEE+ORAM |
| O-Join | 关系型 | 二元equi-join | TEE | |
| Practical O-Join | 关系型 | 综合Join | ORAM | |
| O-Query | 关系型 | 形式化证明:star2: | 算法 |
不经意可搜索加密
CODBS
40th International Symposium on Reliable Distributed Systems (SRDS) 2021
University of Porto 葡萄牙波尔图大学
- 提出一种新的不经意搜索方案CODBS来存储数据库索引,将搜索树拆分为L个较小的ORAM实例,而不是一个较大的ORAM
- 提出了Forest ORAM,这是一种用于存储数据库表的优化ORAM结构
- 提出了一种优化的不经意数据库体系结构,并在PostgreSQL之上实现了一个完整的解决方案
- 形式化证明
POSUP
Proceedings on Privacy Enhancing Technologies; Journal Volume: 2019
Oregon State University 俄勒冈州立大学
POSUP [41] and Oblix [50] explore oblivious indexes over encrypted data using specialized ORAM constructions as building blocks, but do not support general queries.【ObliDB】
使用Intel SGX开发不经意数据结构,在大数据集上提供实用的不经意搜索/更新操作
Oblix
2018 IEEE Symposium on Security and Privacy (SP)
UC Berkeley
POSUP [41] and Oblix [50] explore oblivious indexes over encrypted data using specialized ORAM constructions as building blocks, but do not support general queries.【ObliDB】
不泄露访问模式,并且能够隐藏搜索结果的大小;支持更新(插入和删除),以及多个(可能是恶意的)用户
Preserving Access Pattern Privacy in SGX-Assisted Encrypted Search
27th International Conference on Computer Communication and Networks (ICCCN) 2018
The University of Auckland 奥克兰大学
-
提出了一种SGX辅助的对加密数据进行搜索的方案
-
保护访问模式免受侧通道攻击,同时确保搜索效率(使用了B+树结构来保证搜索效率)
-
处理大型数据库,而不需要在SGX上长期存储(分批加载和处理树索引)
-
与基于oram的解决方案(如obildb)相比,我们的方案要快11倍以上
不经意性证明/分析
Memory trace oblivious program execution
KV数据库TEE
EdgelessDB
开源项目,无相关论文,兼容MySQL
Authenticated key-value stores with hardware enclaves【相关性不大】
- Syracuse University 雪城大学
- 支持查询认证的kv数据库,从而保护数据完整性
- 实现认证LSM树:eLSM(with small query proofs at selective
tree levels),将内存数据存放在enclave外部- 提出基于LSM树的新摘要结构:eLSM摘要,以append方式更新摘要
- 基于Google LevelDB和Facebook RocksDB实现eLSM
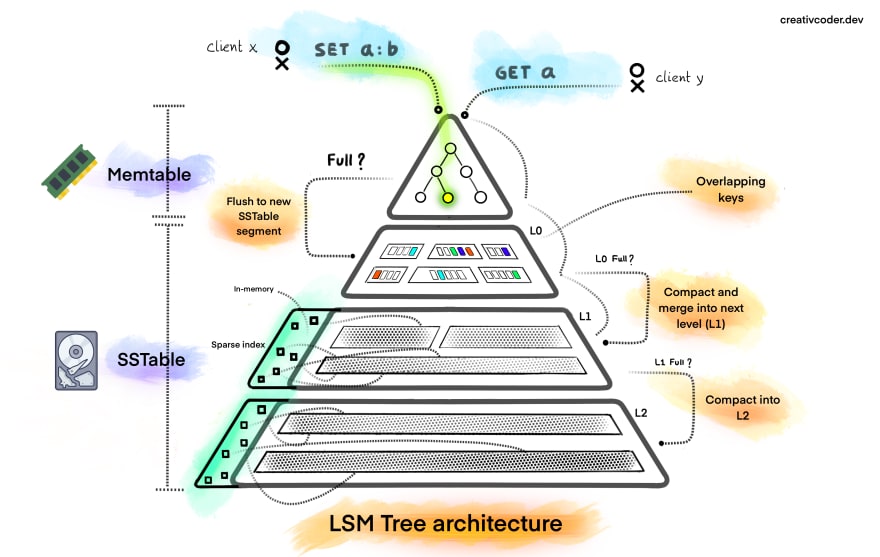
LSM树
适用于写密集型workload
基本增删改查:深入浅出分析LSM树(日志结构合并树) - 知乎 (zhihu.com)
安全定义
- Query integrity:读出的数据是否是之前合法的写请求写入的
- Query completeness:读出的数据是否完整
- Query freshness:读出的数据的时间戳是否最大
Aria
2021 IEEE 37th International Conference on Data Engineering (ICDE)
清华
现实世界的工作负载通常表现出高度倾斜的访问模式:一小部分hot KV pair收到的请求比其他多得多
- 引入基于软件的EPC空间管理器 Secure Cache ,为KV存储提供安全保障和高性能
- 深入研究了命中和未命中惩罚,从而优化了缓存策略
- 基于 Secure Cache 实现Aria,一个不依赖特定index structure的kv数据库
KV存储
- index structure:通过key找到一个KV pair
- hash-based:简单而快速的点查询
- tree-based:支持范围查询(有序存放key)
- storage manager:保存KV pair
通常的设计是:将KV存储直接放在不受信任的内存中,并在EPC中构建安全元数据,以保护KV pair的完整性和机密性。这样的设计基于这样的事实:对不受信任内存中的KV pair或MAC的任何攻击都会导致从其相应计数器计算的MAC与存储在不受信任内存中的MAC之间的KV pair不匹配
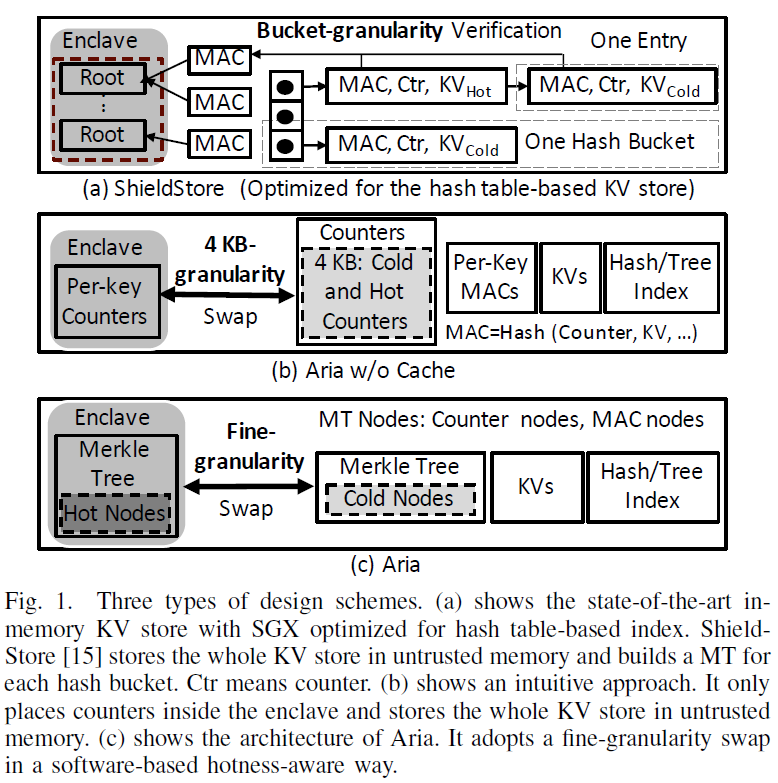
Secure Cache
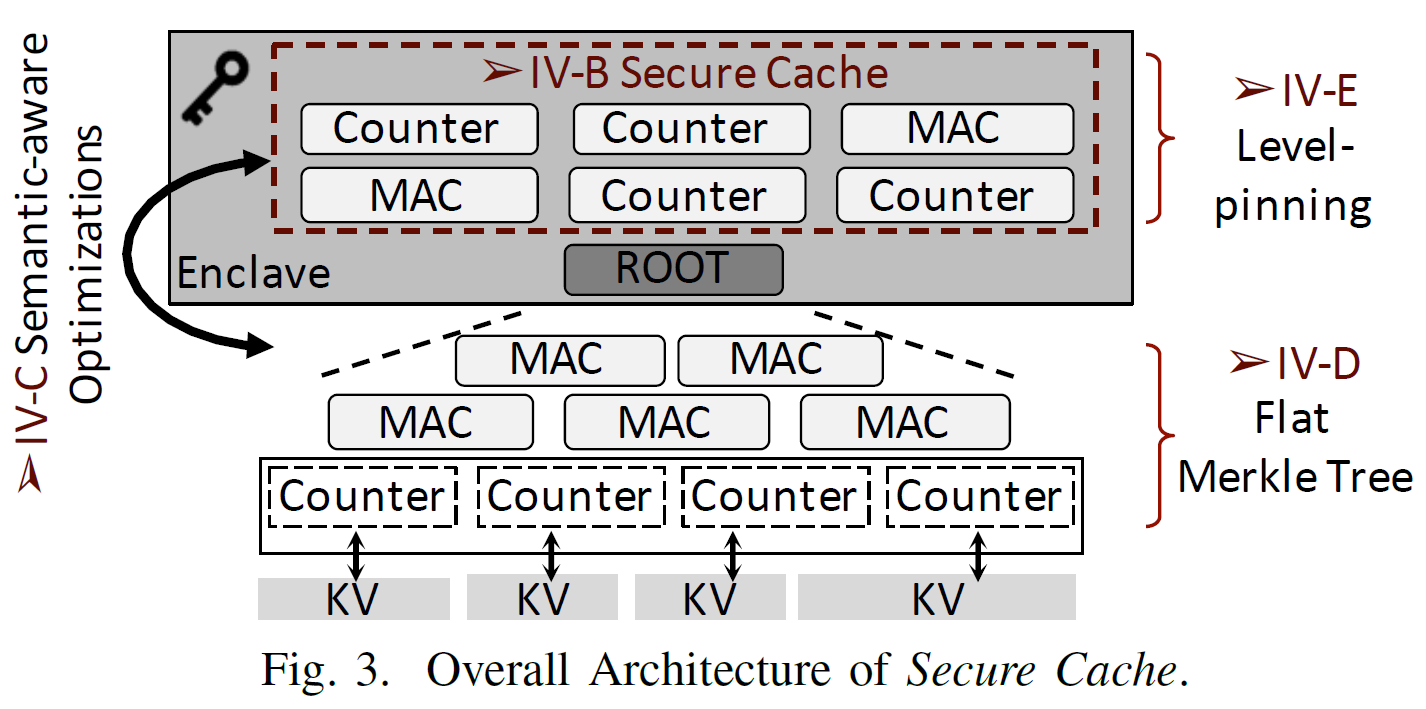
- Secure Cache 用于缓存最经常访问的MT节点,从而在访问这些节点时可以直接从 Secure Cache 里验证,消除了MT验证的开销(叶节点若是要验证,只需要沿着到根节点的路径,找到第一个在缓存中的节点即可)
- 语义优化:
- 消除metadata从enclave内部到外部的加密
- 避免clean缓存项的写回
- 缓存命中优化:
- 将深层的节点固定在 Secure Cache 中(因为验证时用到的概率高)
- 采用FIFO策略来驱逐 Secure Cache 中的节点
- 若命中率小于一个阈值,停止swap
实现
- 连续Merkle树
- 用户空间堆分配器
- 解耦合设计
- 计数器管理
- Put和Get实例
- 每次get需要解密多个kv pair才能得到想要的结果,是否有优化空间?
SPEICHER
17th USENIX Conference on File and Storage Technologies (FAST 19) 2019
The University of Edinburgh 爱丁堡大学
基于LSM树的三个设计更改:【Tweezer】
- 必须调整MemTable以减少EPC的使用。Speicher重新设计了MemTable,使它的大部分(叶上的值)显式地存储在EPC外部,并具有加密保护
- I/O调用必须由另一个线程在用户级别上处理,以避免在每次调用时都离开enclave上下文。Speicher使用基于Intel SPDK[1]的直接I/O库运行,这减少了额外上下文切换的成本
- KVS应该有适当的时间戳,以击败回滚和分叉攻击。Speicher使用自己的异步单调计数器包装同步SGX单调计数器
- 用于屏蔽执行的I/O库:I/O库在不退出enclave的情况下执行I/O操作
- SPEICHER基于屏蔽执行框架SCONE实现
- 异步可信单调计数器:确保数据新鲜度,利用KV存储中同步操作的延迟来异步更新计数器
- 安全LSM数据结构:部署在enclave外部,并保证完整性,机密性和新鲜性
- 算法:设计和实现持久化KV数据库的操作:get, put, range queries, iterators, compaction, restore
威胁模型
- 敌手可以控制整个系统软件堆栈,包括操作系统或虚拟机监控程序,并能够发起物理攻击,例如执行内存探测
- 防止回滚攻击和分叉攻击
- 无法抵御侧信道攻击
设计挑战
- 有限EPC大小:EPC分页切换开销大,因此需要将MemTable放在enclave外部,同时保证安全
- 不可信的存储介质:存储引擎持久化三种文件:SSTable,WAL,Manifest,需要保证这三种文件的安全(SGX本身不提供对有状态计算的安全保证),因此重新设计LSM数据结构
- 昂贵的I/O系统调用:SCONE提供异步系统调用接口,但不适合需要支持频繁I/O系统调用的存储系统,因此设计了一种新的I/O机制
- 可信计数器:用于保护存储在不可信存储介质中的数据的新鲜性,SGX可信计数器十分慢,因此设计了异步可信单调计数器
Overview
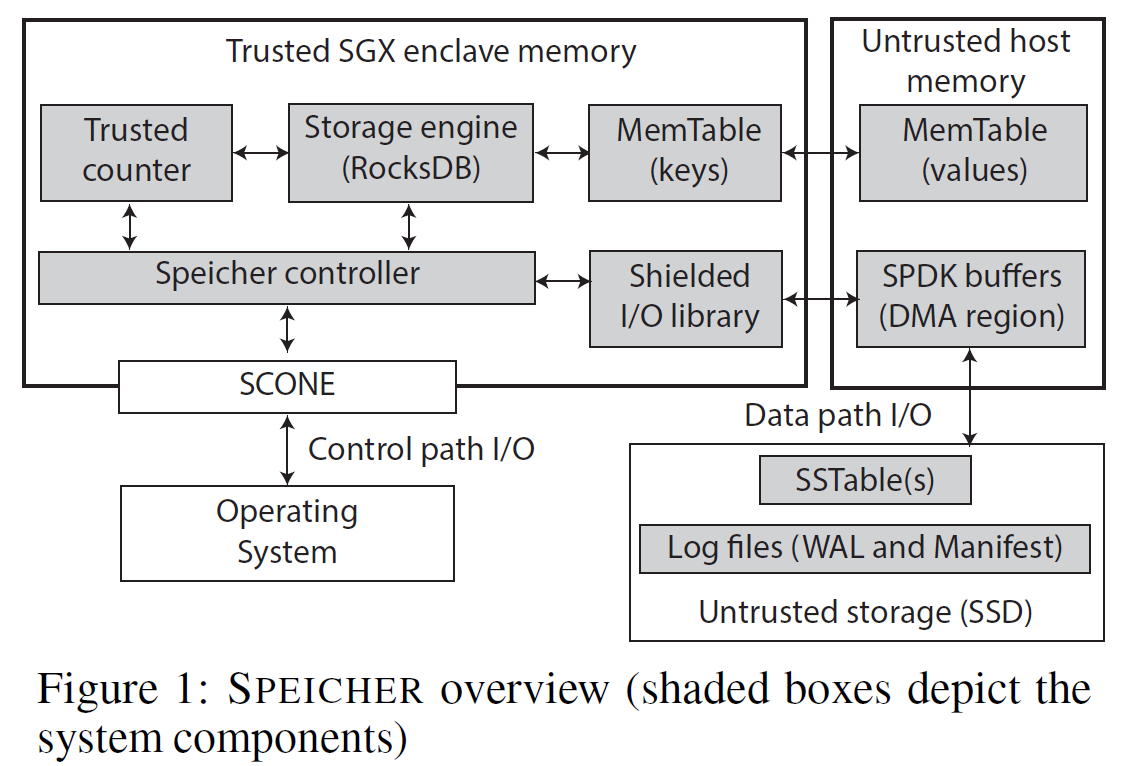
-
SPEICHER controller:基于SCONE实现,提供可信执行环境、远程认证、enclave内部用户级多线程和内存管理的运行时支持
-
屏蔽I/O库:从enclave内部直接访问磁盘,而不需要昂贵的exit操作,通过SPDK实现
-
可信计数器:防止回滚攻击,设计异步单调计数器AMC
-
MemTable:key存放在enclave中的跳表里,value加密存放在不可信内存【存在线性增长导致EPC页切换的问题】
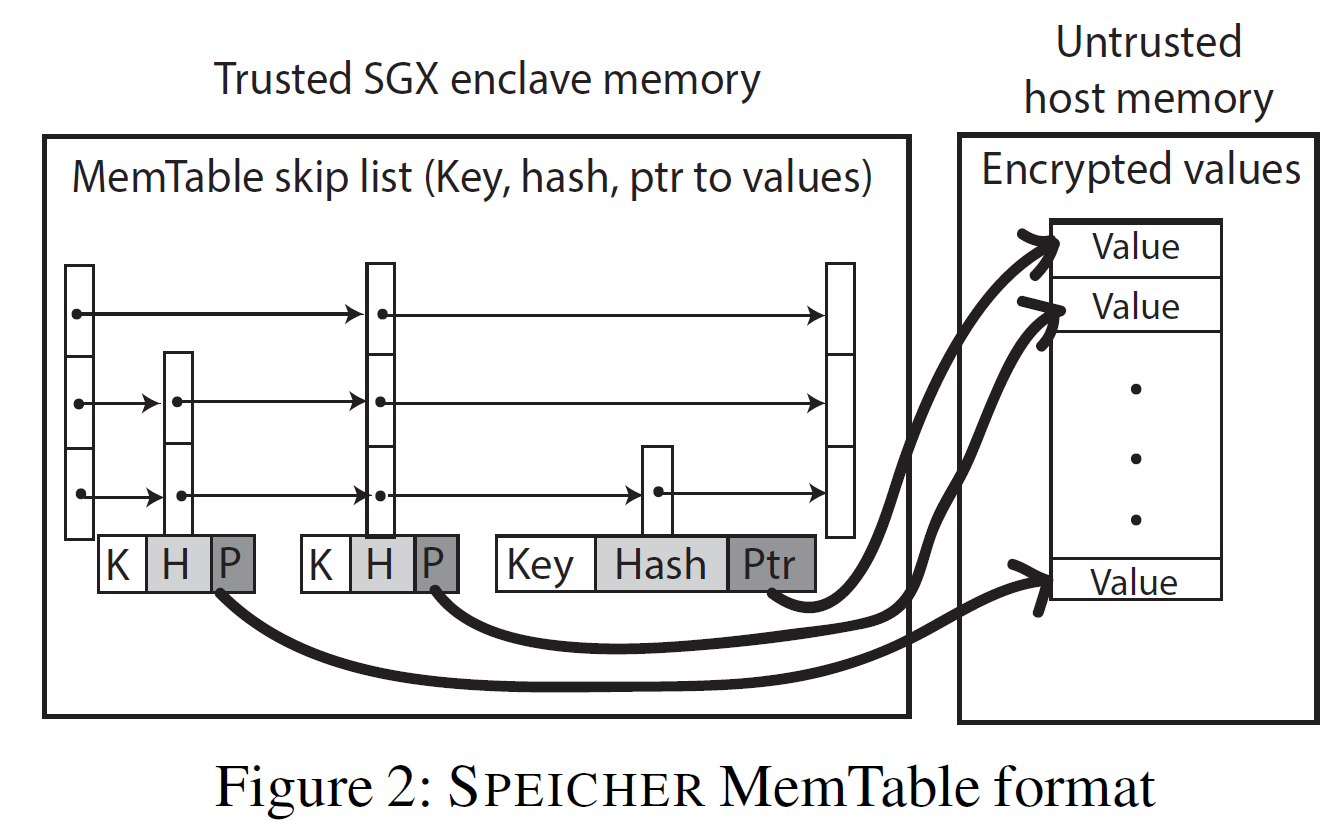
-
SSTable:KV按序排列并经过加密,每个block的hash存放在footer,footer的hash记录在enclave中的Manifest中从而确保新鲜性
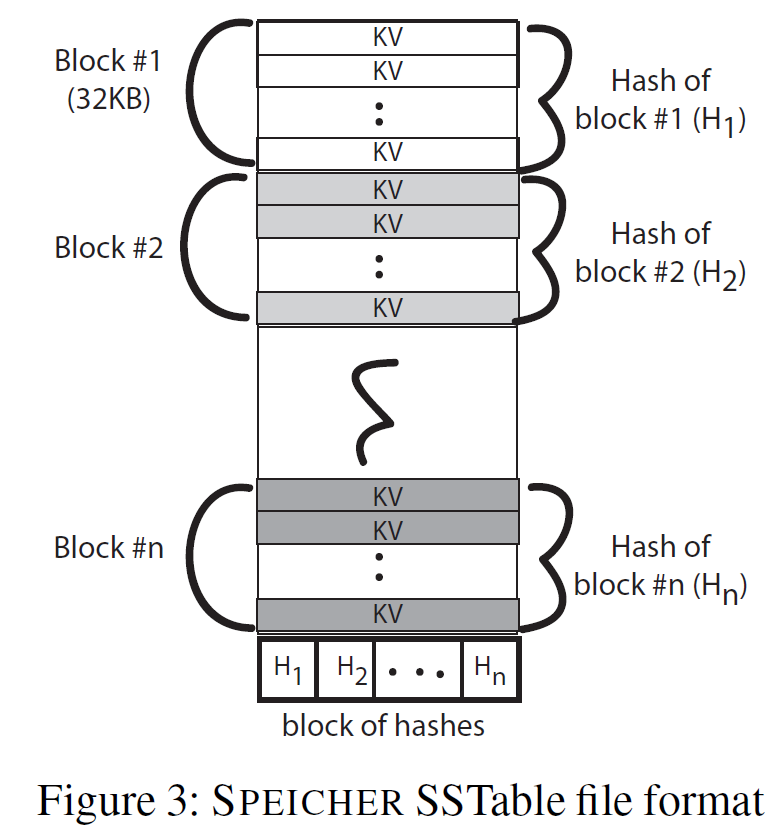
-
Log文件:append-only
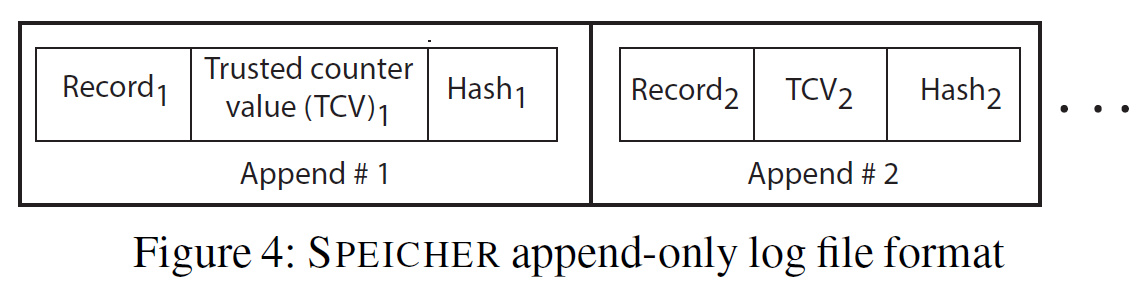 - WAL:存放插入的KV pair直到top-level compaction,用于restore WAL
- Manifest:跟踪实时文件
- WAL:存放插入的KV pair直到top-level compaction,用于restore WAL
- Manifest:跟踪实时文件
算法
- Put:将KV pair添加到WAL,然后写到MemTable
- Get:需要生成存在证明或不存在证明
- Range queries:根据start key构建Iterator进行遍历,对于每个key,找到最顶层的value
- Iterators
- Restore:收集所有属于KV存储的文件(通过读取Manifest),然后重放所有变化到MemTable
- Compaction
EnclaveCache
Proceedings of the 20th International Middleware Conference 2019
SJTU
对多租户云环境的KV数据库进行用户隔离等保护【不相关】
ShieldStore:star2:
Proceedings of the Fourteenth EuroSys Conference 2019
School of Computing, KAIST 韩国科学技术院
随着密钥空间的增长,ShieldStore由于bucket变长而承受着巨大的验证开销【Aria】
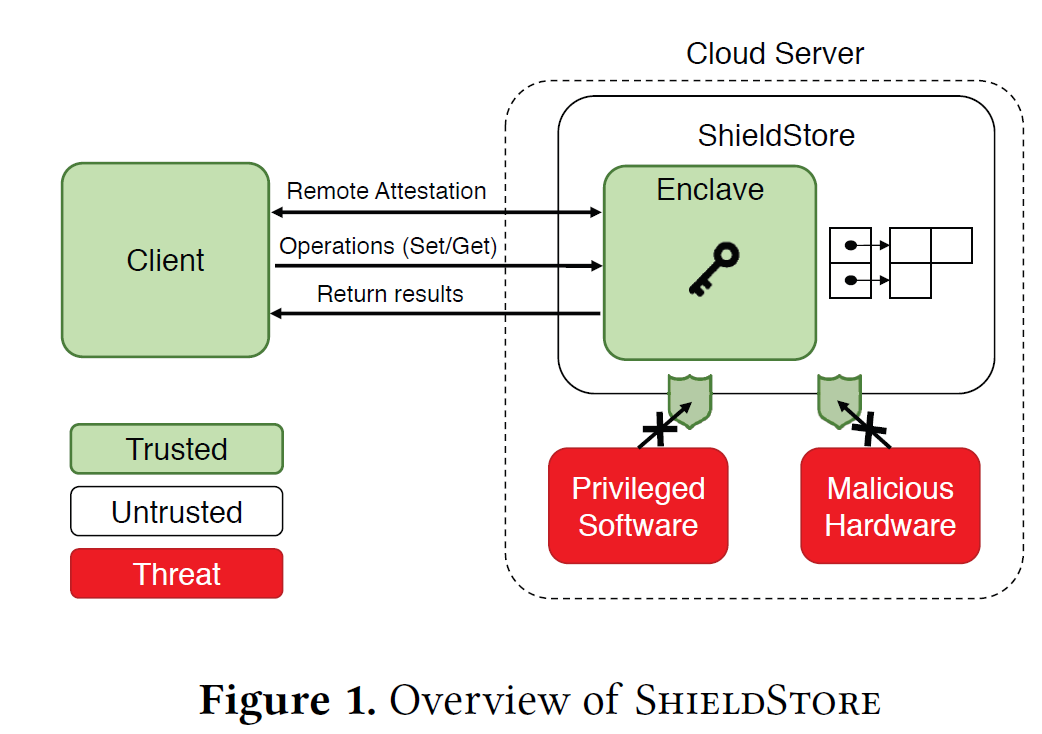
Baseline kv存储
【不是直接用业界成熟的kv数据库,而是自己实现一个简单版本的内存kv存储】
- 基于哈希的索引结构:高效点查询,范围查询困难
- 为相同的哈希值创建链表,来抗碰撞
- server-side加密和计算数据
Overview
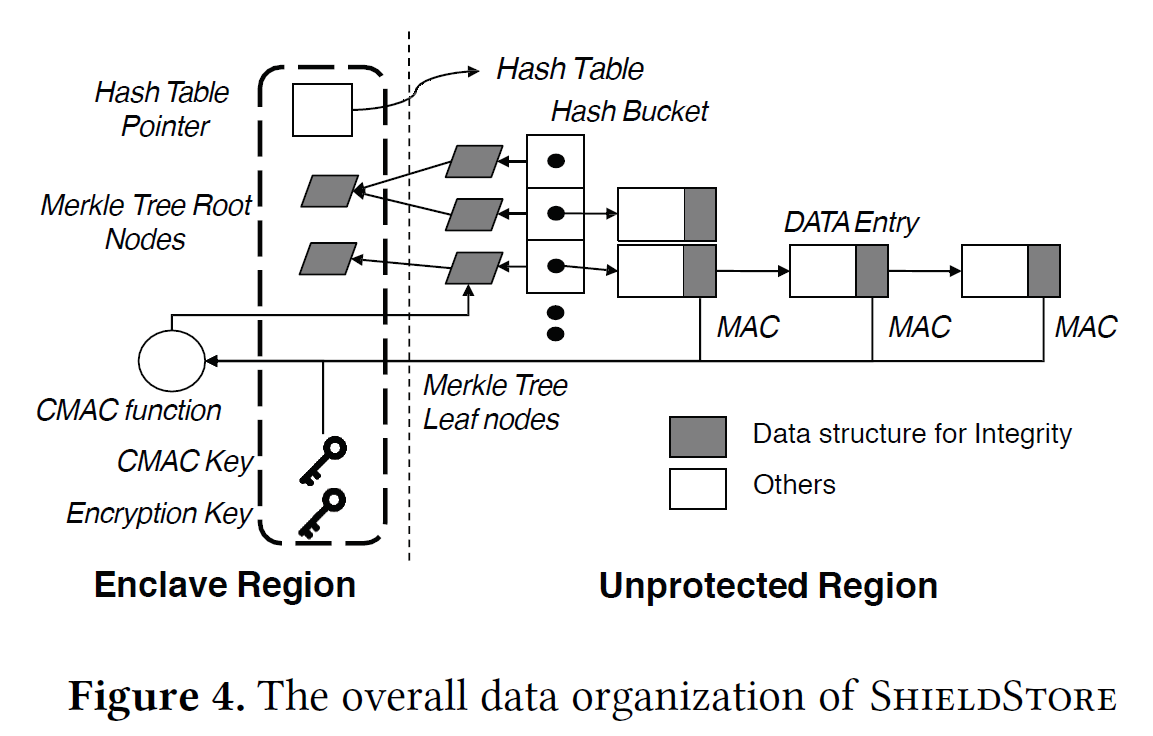
只将主要的密钥和meta-data存放在enclave中,主哈希表经过加密后存放在非可信区
设计
key-value加密
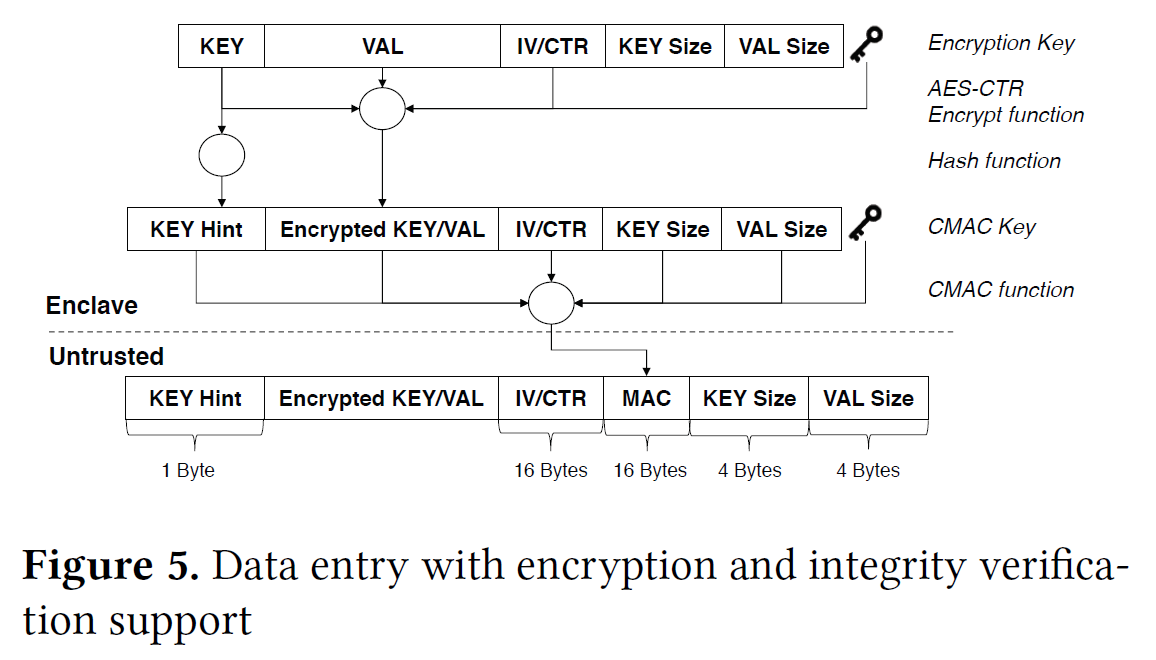
- 通过对hash索引使用keyed-hash函数,可以将hashed键分布中的信息泄漏降至最低【进一步优化?】
- 通过key hint来在一个bucket中快速找到对应的value
- 若一个key更新,IV/counter会增加;若创建新的kv pair,会插入到bucket的头部
完整性校验
对每个bucket set维护一个Merkle root,而不是对所有kv pair维护一个Merkle tree【时间、空间复杂度分析?】
持久化
周期性snapshot
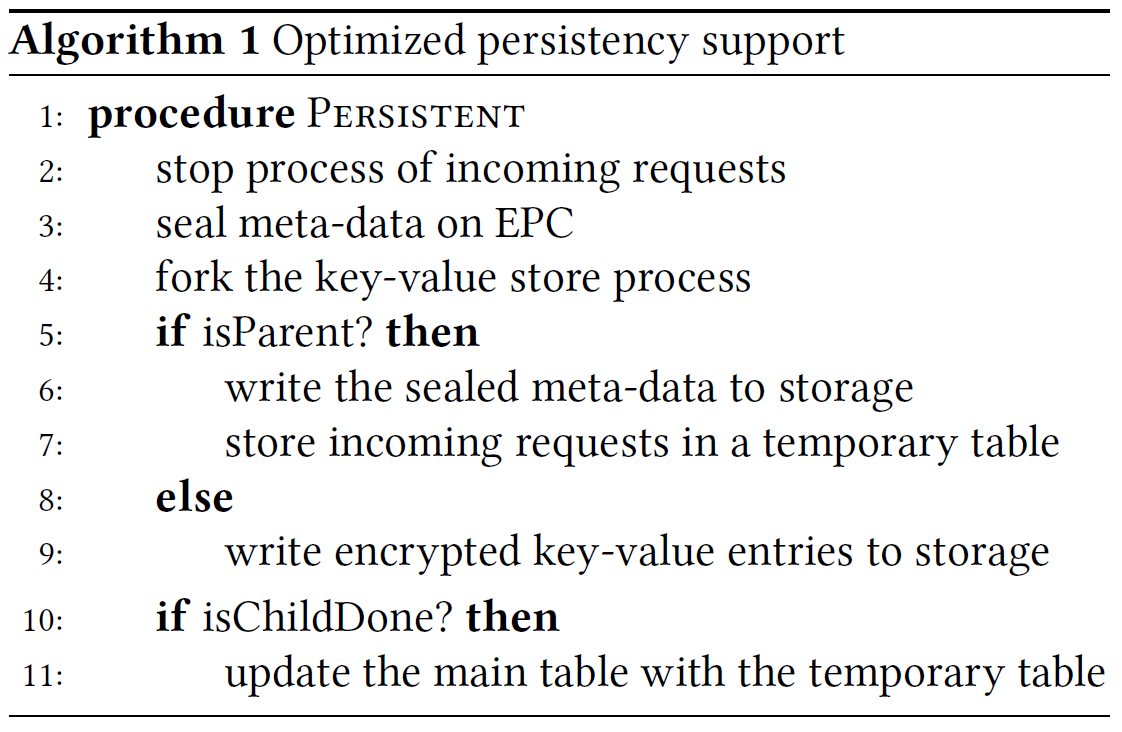
- parent进程密封enclave内的meta-data,child进程直接存储不可信内存中的哈希表
- 在snapshot的同时处理新的请求,使用临时表
- 使用SGX提供的单调计时器防止回滚攻击【使用效率更高的安全计时器?】
优化
- 额外的堆分配器:在enclave内运行,分配外部不可信内存(为了减少OCALL)
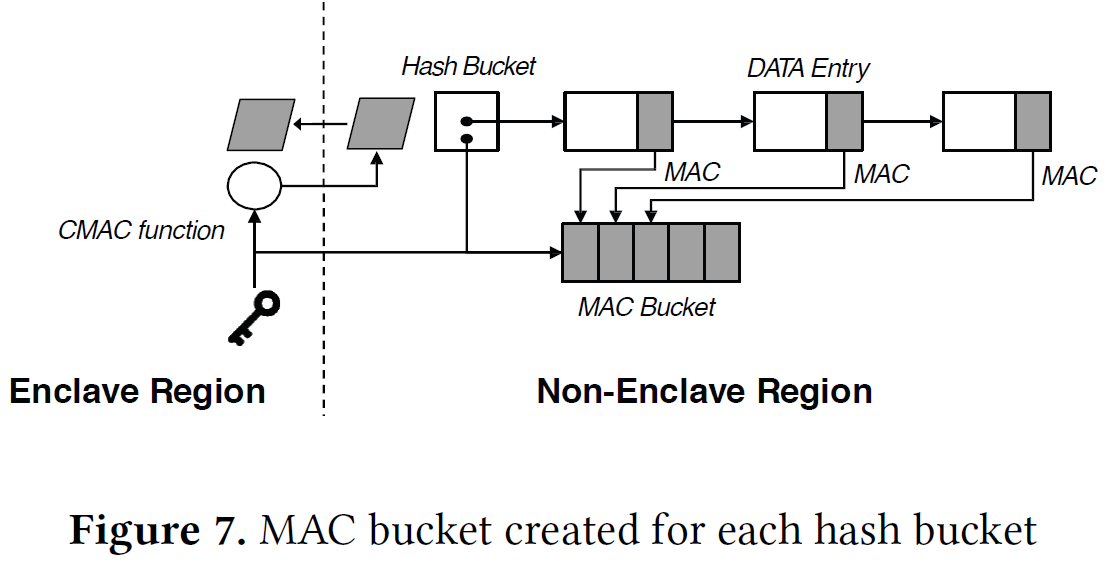
- MAC bucket:每个hash bucket维护一个,用来存放每个条目的MAC,从而快速计算merkle proof 而不用遍历整个chain
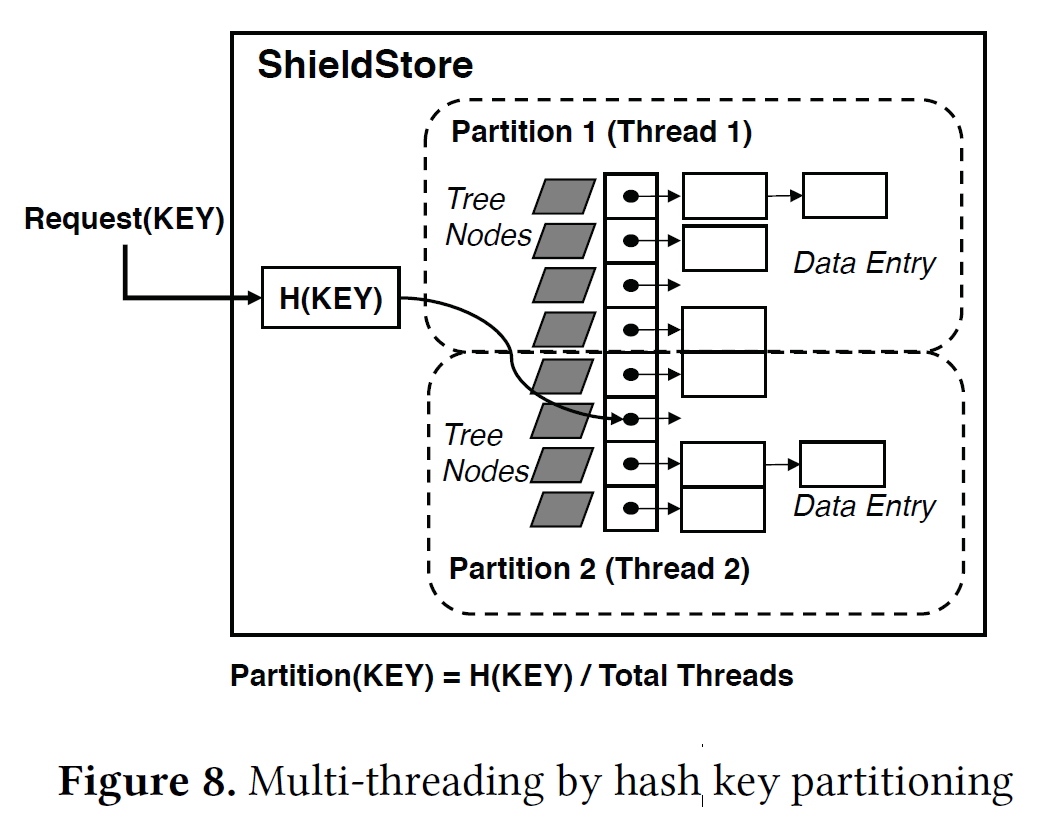
- 多线程:不同的线程处理不同的hash key,从而避免同步,但线程数量只能固定,不能动态变化【使用Occlum改进?】
- 搜索加密的key:使用1字节明文key的hash作为hint,从而减少需要解密的次数(只对匹配hint的key进行解密来判断是否是target key)
ZeroTrace:star2:
NDSS 2018
University of Waterloo 滑铁卢大学
ZeroTrace[66]在set/dictionary/list接口上提供了一个新的不经意的get/put/insert操作库【Practical O-Join】
- 设计和实现了一个不经意内存管理器
- 设计和实现 ZeroTrace,一个用来不经意处理数据结构的库
安全威胁
- enclave内对外部内存的访问是完全暴露于server的
- enclave内部的执行不能保证不经意性
- server可以随时终止enclave从而造成某些攻击
- 不抵抗硬件攻击、硬件制造的漏洞、拒绝服务攻击
定义
- enclave执行的不经意性(计算不可区分)
- SGX的安全挑战
- 软件侧信道
- 不能对超出EPC范围的存储提供隐私/完整性保护
- 没有直接的IO/系统调用
- SGX的性能挑战
- EPC大小限制
- 可信区和不可信区切换
- ORAM正确性和安全性定义(可忽略函数/计算不可区分)
ZeroTrace内存控制器
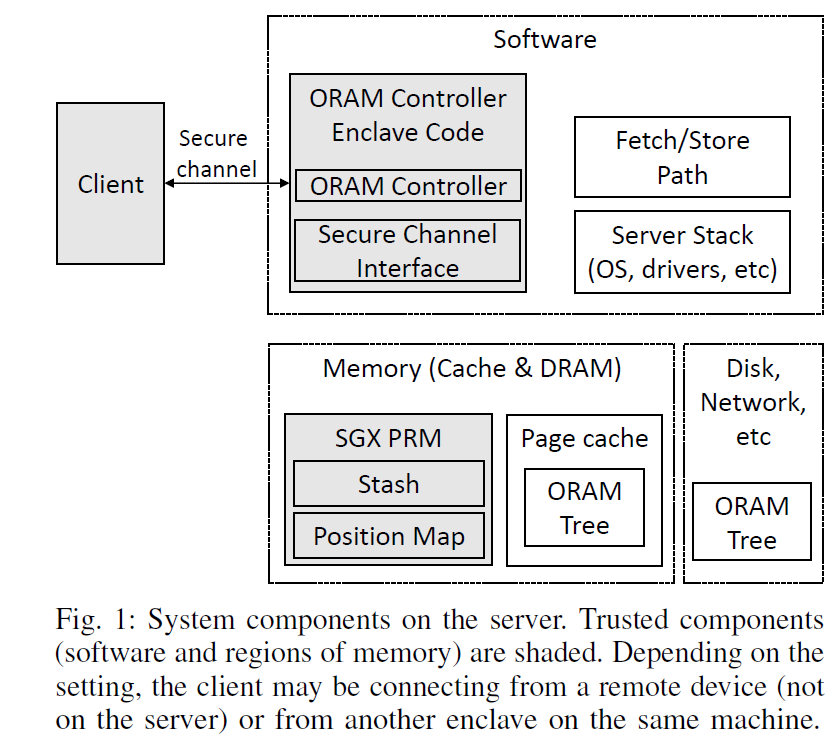
-
client接口:
read(addr)和write(addr, data) -
server处理:
FetchPath(leaf)和StorePath(tpath, leaf) -
内存管理器enclave程序:
-
初始化:将程序加载到enclave中
-
构筑块:
- 不经意函数:根据汇编级别的函数库构建ORAM控制器
- 加密和哈希:使用AES-NI和SHA-256
-
ORAM控制器:处理client请求
(op, id, data*)- 不经意leaf-label检索
- 不经意block检索
- 不经意path重建
-
-
Fetch/Store path优化
- 使用多个磁盘扩展带宽
- 缓存ORAM树的顶层
-
安全性分析(informal)
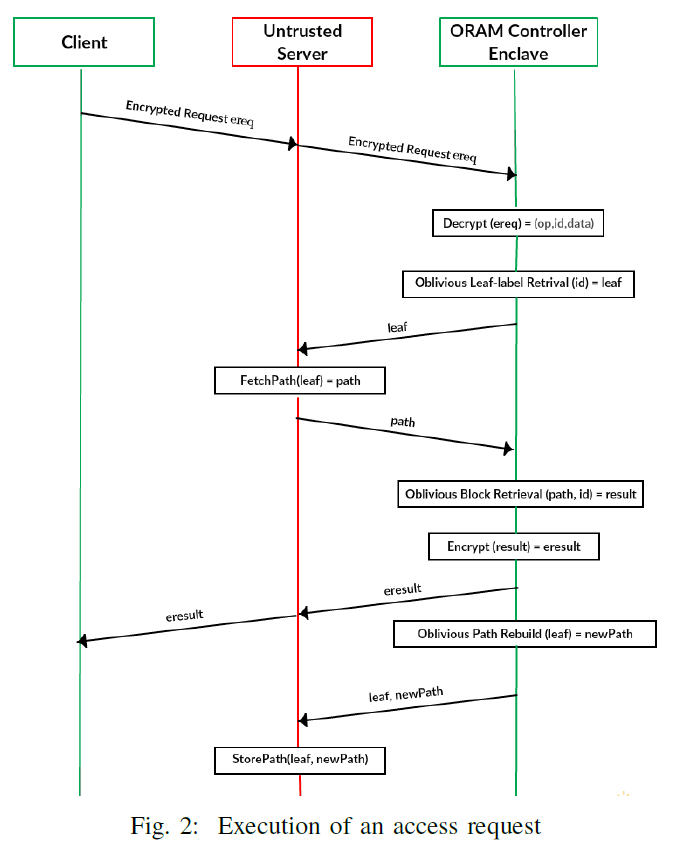
持久化的完整性
- 定义fault tolerance的enclave协议
- functionality和security
- 抵抗mix-and-match攻击
- 抵抗重放攻击
Precursor
Proceedings of the 22nd International Middleware Conference 2021
TU Braunschweig 布伦瑞克工业大学 德国
-
利用TEE来提供保密性和完整性,同时依赖于RDMA进行低延迟和高带宽通信
-
将加密操作放在客户端,以防止服务器端CPU瓶颈
-
尽可能避免昂贵的TEE上下文切换,即安全区和非安全区的切换
TEE-KV
Proceedings of the ACM Symposium on Cloud Computing 2018
Tokyo University of Agriculture and Technology 东京农工大 & 蚂蚁 & Microsoft Research Asia 微软亚洲研究院
【只有一个Abstract,这是个啥?】
Oblivious key-value stores and amplification for private set intersection
Annual International Cryptology Conference 2021
Oregon State University 俄勒冈州立大学
【形式化证明,没有用到SGX】
-
引入了无关键值存储(OKVS)的抽象,确定并形式化了允许OKVS接入不同协议的重要属性
-
描述了放大技术,可以用来将较弱的OKVS引导为强OKVS
Tweezer
- 20th USENIX Conference on File and Storage Technologies (fast22)
- UNIST 韩国蔚山科学技术学院
- 在Speicher基础上修改
- 根据Speicher论文自己实现了一个Speicher版本
- TWEEZER比Speicher性能高出1.94 ~ 6.23×,使得由于机密计算导致的性能开销从16 ~ 30×减少到4 ~ 9×
不同于Speicher的三个关键设计
- 无需构建横跨SSTable的Merkle树来确保LSM树的新鲜度,而是对不同的SSTable采用不同的key进行身份认证,使得攻击者无法在当前SSTable以外的任何地方找到其他数据块来执行重放攻击
- Tweezer为每个SSTable创建并关联一个唯一的MAC key,基于LSM树的三个属性:每个SSTable的不可变性、每个Level的键的唯一性和每个数据块中的排序键
- 每个数据块中键的顺序都是唯一且不变的,这使得Tweezer可以检测到任何对新鲜度的攻击,而无需为每个SSTable生成Merkle树
- 将MAC与每个键值对相关联,而不是与SSTable中的每个数据块相关联。Tweezer通过分别对每个键值对进行加密和身份验证,减少了EPC使用中的读放大。
- 使用哈希链来对日志文件(WAL和Manifest)进行身份认证,而不使用计数器,Tweezer要求用户放置一个心跳事务来作为时间戳记录KVS版本,并在以后使用它来验证Tweezer的快照是否是最新的